인간의 말을 컴퓨터가 이해할 수 있도록 하기 위한 '벡터화'의 이야기
인간의 말을 컴퓨터가 이해하는 방법은 인공지능 분야 중 자연어 처리(Natural Language Processing, NLP) 기술을 이용하는 것입니다.
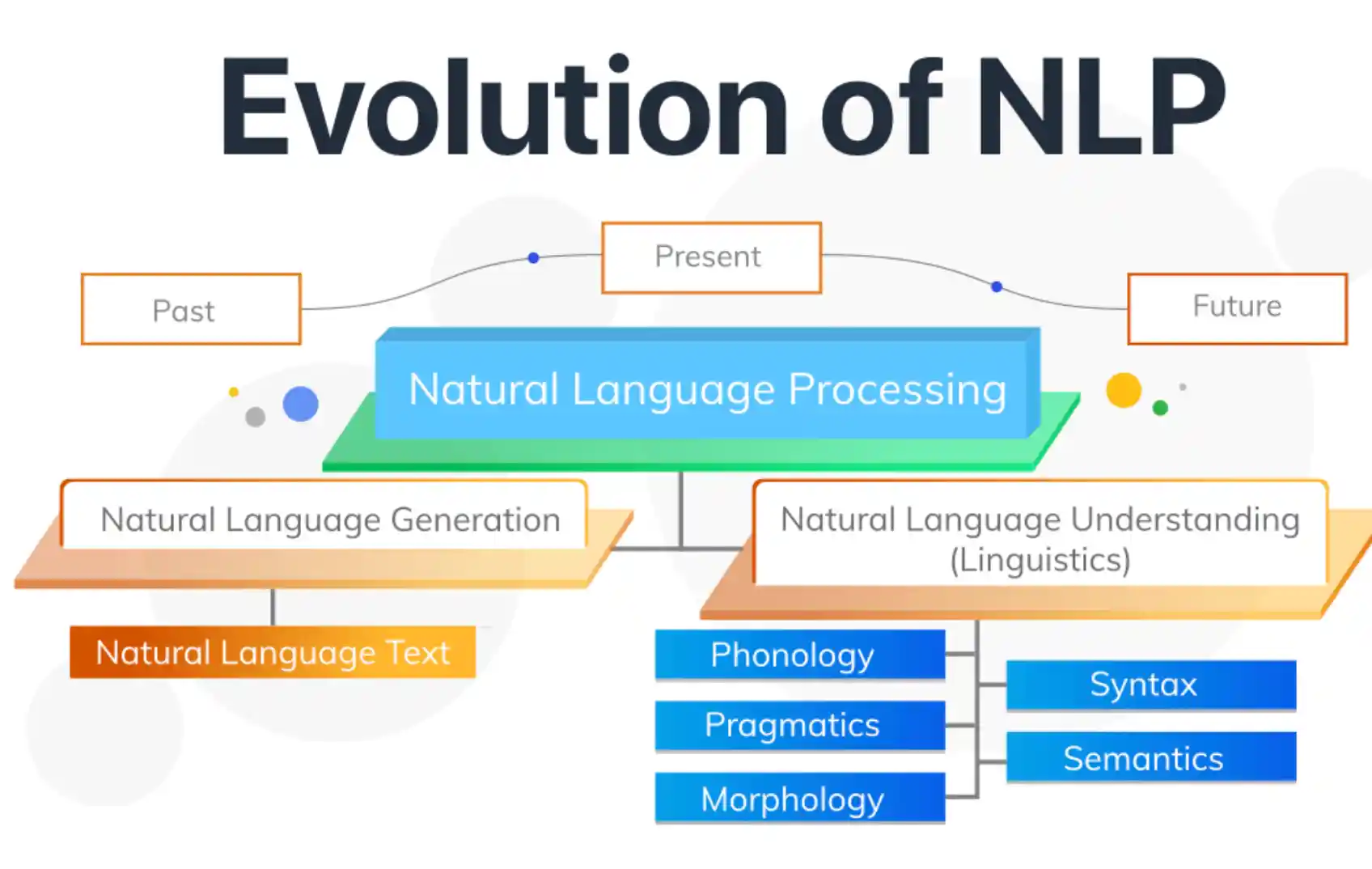
NLP 기술은 인간이 사용하는 언어를 컴퓨터가 이해할 수 있는 형태로 변환하고, 이를 분석하여 컴퓨터가 의미를 파악하도록 합니다. 이를 위해 자연어 이해, 자연어 생성, 문서 분류, 감성 분석 등 다양한 기술과 알고리즘이 사용됩니다.
최근에는 딥러닝을 이용한 NLP 기술도 많이 연구되고 있습니다.
우리에겐 인공지능이라고 하면 이전 이세돌과 바둑을 두던 알파고의 기억이 너무나 강해서 딥러링이라는 분야만 생각하게 됩니다. 물론 인공지능에 있어 가장 중요한 학습 기능이며 핵심 기술입니다. 기계학습의 딥러닝은 뭔가 복잡한 그림들이 이어지는 케이스단위의 학습을 나타내고 있습니다.
하지만, 딥러닝되어 학습된 내역으로 들어가기 위해서는 인간의 언어를 컴퓨터가 이해하도록 처리주는 작업들이 필요합니다. 인공지능 이전부터 컴퓨터 공학에서 연구 분야이던 자연어 처리 부분에 대한 세부내역을 알아보도록 하려 합니다.
조금 어려운 이야기처럼 들리지만, 찬찬히 읽어 보시면 이후 다른 인공지능 이야기가 나올떄 꽤 도움이 되시니 조금만 시간을 가지고 관심을 가져주었으면 합니다.
먼저 자연어 처리에 대한 내역을 개략적으로 살펴보면,
자연어 처리(Natural Language Processing, NLP)는 크게 다음과 같은 4 단계로 구성됩니다:
- 형태소 분석(Morphological Analysis): 문장을 단어로 분리하고, 각 단어의 형태소(의미를 가지는 최소 단위)를 파악합니다.
- 구문 분석(Syntactic Analysis): 문장의 구조를 분석하여, 구문론적 구조를 파악합니다.
- 의미 분석(Semantic Analysis): 문장에 담긴 의미를 이해하고, 분석합니다.
- 문맥 분석(Pragmatic Analysis): 문맥, 상황, 발화자의 의도 등을 고려하여, 문장의 의미를 파악합니다.
이러한 4단계들을 통해 자연어 처리 기술은 우리가 사용하는 언어를 이해하고, 자연어 데이터를 분석하고 처리할 수 있습니다. 여기서 자연어란 우리가 사용하는 인간들의 언어입니다.
한국어든 일본어나 영어든 상관없습니다. 물론 언어에 따라 문법과 문맥판단이 조금 다르긴 하지만, 기본적인 처리 단계는 모두 동일합니다.

자연어 처리란 무엇인가?
우선, 자연 언어 처리란 무엇인가에 대해 간단히 이야기하겠습니다.
컴퓨터는 기본적으로 프로그램 언어(인공 언어)를 사용해 지시를 받아 처리를 실행하는 것입니다.
대조적으로, 우리가 평상시 사용하고 있는 한국어, 일본어나 영어 등의 언어는 자연 언어라고 불리는 언어가 되고 있습니다.
컴퓨터는 기본적으로 자연어를 이해하기 위해 만들어지지 않았습니다.
만약 여기서 「집에 있는 카카오를 부르면 제대로 이해해 준다고」 생각하는 분도 있을지도 모릅니다.
이것이 성립하기 위해서는 자연언어 처리 라고 불리는 기술이 선행되어 적용되고 있는 것입니다.
즉 자연언어 처리는 자연언어를 컴퓨터에 이해할 수 있도록 하여 처리시키는 기술이라고 할 수 있습니다.
자연 언어 처리를 위한 4가지 처리 프로세스
대략적으로 나누어 자연 언어 처리에는 네 가지 처리 프로세스가 있습니다.
형태소 분석
형태소 해석은 문서를 의미를 가진 최소 단위(형태소)로 분해하여 품사를 할당하는 것입니다.
자세하게 설명을 해보자면, 형태소 분석은 자연어 처리 과정 중 하나로, 문장을 구성하는 최소 단위인 형태소를 분석하는 작업입니다.
이 과정에서 단어의 형태와 의미를 파악할 수 있습니다. 대표적으로는 형태소의 품사를 태깅하는 POS tagging이 있습니다.
예를 들어, "I am a student"이라는 문장에서, "I", "am", "a", "student"는 각각 단어이자 형태소이며, 그 중 "I"와 "student"는 명사, "am"은 동사, "a"는 관사로 태깅됩니다.
구문 분석
구문 분석은 형태소 해석으로 분해한 형태소를 절의 단위로 정리하여 각각의 관계성을 해석하는 것입니다.
구문 분석은 문장을 구성하는 단어들 간의 문법적 관계를 분석하여 문장의 구조를 파악하는 과정입니다. 구문 분석은 토큰화와 형태소 분석을 거쳐 분석되며, 분석된 구조는 구문 트리(Syntax Tree) 또는 의미 구조(Semantic Structure)의 형태로 표현될 수 있습니다. 구문 분석은 자연어 이해와 자연어 생성 모두에 중요한 역할을 합니다.
예를 들면 「나」 「는」 「고양이」 「다」라고 형태소 해석으로 분해한 것을, 「나는」 「고양이다」라고 절의 단위에 정리합니다.
이 「나는」 「고양이다」에 관해서는, 「나는」이 주어, 「고양이다」가 술어의 관계라고 할 수 있습니다.
또 다른 예로서, 「귀여운」 「고양이」와 형태소 해석으로 분해한 것이 있었을 때, 「귀여운」 「고양이」가 문절의 단위가 됩니다. 형태소 단체로 문절이 될 수도 있습니다.
그리고 이 「귀여운」 「고양이」에 관해서는 「귀여운」이 「고양이」에 대한 수식어로 「고양이」는 피수식어의 관계가 됩니다.
의미 분석
의미 해석은, 구문 분석으로 해석한 문서가 어떠한 의미를 가지는지를 해석하는 것입니다.
문법적으로는 있을 수 있어도 문서적으로는 성립하지 않는 구문을 단어의 의미 등으로부터 판단할 수 있습니다.
의미 분석(Semantic Analysis)은 자연어 처리의 단계 중 하나로, 문장의 의미와 관련된 정보를 추출하는 작업입니다. 이 단계에서는 단어들의 의미와 문맥, 관련된 지식 등을 고려하여 문장 전체의 의미를 파악하려고 합니다.
의미 분석을 수행하는 방법에는 다양한 기법이 사용될 수 있습니다. 예를 들어, 단어의 시소러스(Thesaurus)를 이용하거나, 워드넷(WordNet)과 같은 단어 간의 관련성 정보를 활용할 수 있습니다. 최근에는 딥러닝 모델을 사용하여 문장에서 단어들 간의 관계를 추출하고, 이를 바탕으로 문장의 의미를 추론하는 방법도 많이 사용됩니다.
예를 들어 「머리가 붉은 물고기를 먹는 고양이」의 이야기를 인터넷에서 본 적이 있으신가요?
처음 들었다는 분은 아래 그림을 한번 보시면 이해가 되실겁니다. 아니면 "아버지가방에들어가신다" 같은 오래된 이야기도 있구요. 어디서 끊어 읽는냐의 문제인거죠.
해석의 단계에서는 「머리가」가 「붉은 물고기를 먹는 고양이」에 관련되는, 고양이가 머리로 붉은 물고기를 먹는다고 하는 의미의 문서도 성립하게 됩니다. 그러나, 현재는 이 세계에서 머리로 물고기를 먹는 고양이는 존재하지 않습니다.
단어의 의미로부터 이런 것을 판단해 성립하는 문서를 해석하는 것이 의미 해석이 되고 있습니다.
하지만, 진짜 빨간 머리의 고양이를 이야기 하거나 한다면 완전히 다른 이야기가 되어가는 거죠.

문맥 해석
문맥 해석은 복수의 문서간의 관계성과 그에 따라 어떤 의미를 가지는지를 해석하는 것입니다.
문맥 해석(Contextual analysis)은 자연어 처리의 마지막 단계로, 이전에 수행된 형태소 분석, 구문 분석, 의미 분석 결과를 바탕으로 문장 전체의 문맥을 고려하여 최종적인 결과를 도출하는 단계입니다.
이 과정에서 단어나 구문의 의미가 바뀌는 경우를 파악하고, 그에 따른 올바른 해석을 선택하는 등 문장의 의미를 완전히 파악하기 위한 작업을 수행합니다. 이를 통해 자연어 처리 시스템은 보다 정확하고 자연스러운 결과를 도출할 수 있습니다.
예를 들어, 다음과 같은 단어로 여러 의미를 가지는 것이 있습니다.
「양생」이라고 하는 단어에는, 「병에 걸리지 않도록 건강관리를 잘 하는 것 즉 몸을 소중히 관리한다」라고 하는 의미와 「토목 공사로 굳어지지 않는 콘크리트를 보호하는, 건축으로 기둥이나 벽에 상처가 나지 않도록 보호한다」라고 하는 2가지 의미가 존재합니다. “여기 양생해 두어”라고 말했을 때, 우리는 이것을 듣고 “이 장소를 양생 한다고 말한 문맥에 잡히기 때문에 후자의 양생이구나”라고 이해할 수 있습니다.
이것은 한자를 많이 사용하는 한국어나 일본어의 예이지만, 영어에서도 같은 단어로 여러 의미를 가지는 것이 있습니다.
이렇게 말한 문서의 화제를 읽고 컴퓨터가 적절한 단어의 의미를 이해할 수 있도록 문맥 분석이 있습니다.
4개의 처리 프로세스는 내용에서 봐도 알 수 있듯이, 심플한 형태소 해석이 제일 정밀도도 높게 이해하기 쉬운 것이 되고 있습니다.그리고 구문 해석·의미 해석·문맥 해석과 보다 길고 복잡한 문서를 해석하게 되어, 정밀도도 낮아져 가는 경향이 있습니다.
형태소 해석을 함으로써 할 수 있게 되는 것
형태소 해석을 실시하는 것으로, 문서를 「수치화 (이하 벡터화) 할 수가 있게 됩니다.
영어 등은 원래 공백으로 구분하여 단어가 분할되어 있으므로 이를 하지 않아도 벡터화할 수 있습니다.
문서에 대해서는, 그 밖에 다양한 전처리(표기 흔들림을 통일하는 정규화나 단체에서는 의미를 가지지 않는 조사·조동사를 제거한다)를 실시할 필요가 있습니다.
또한 문서와 같이 이미지나 음성이라는 데이터도 벡터화할 수 있습니다.
예를 들어,
- png나 jpg 등의 래스터 데이터는 픽셀의 집합체로 되어 있어, 픽셀의 농담을 수치로 표현해 배열에 격납한다
- 음성을 푸리에 변환을 이용하여 주파수 데이터로 설정
라고 말한 처리를 실시하는 것으로 벡터화할 수 있습니다.
벡터화하면 기계 학습의 입력으로 사용할 수 있습니다.
보다 정확하게 말하면, 효율적으로 학습을 진행할 수 있는 입력으로서 이용할 수 있게 된다고 말한 곳입니까. 또, 벡터가 된 데이터는 각각의 관련성을 조사할 수 있게 됩니다.

자연 언어에서 벡터화 기술에 대해
벡터화 처리에 에 대해서는 크게 나누어 두 가지 방법이 있습니다.
자연 언어에서 벡터화 기술은 단어나 문장을 숫자 벡터로 변환하는 기술을 말합니다. 이를 통해 자연어 처리 기술에서 사용되는 기계 학습 모델에 입력으로 활용할 수 있습니다.
이를 위해 대표적인 방법으로는 Word2Vec, GloVe, FastText 등이 있습니다. 이러한 방법들은 단어의 의미나 문맥을 파악하여 벡터로 표현하므로, 이를 이용해 자연어 처리 분야에서 다양한 문제를 해결할 수 있습니다.
카운트 기반 기술
이것은 코퍼스라고 불리는 자연언어처리의 연구에 이용하기 위해 집적된 구조화되어 정보를 부여한 대량의 텍스트데이터를 이용하여 이루어지는 기법입니다.
이하, 유명한 2종류의 카운트 베이스의 기법에 대해 소개합니다.
- Bag of Words (BoW)
BoW는 형태소 해석으로 분할한 단어를 문서마다 몇 번 출현했는지를 세어 벡터로 하는 수법입니다.
이 수법을 실시하기 전에, 전술한 전처리(표기 흔들림을 통일하는 정규화나 단체에서는 의미를 가지지 않는 조사·조동사를 제거한다)를 확실히 실시해 둘 필요가 있습니다. 전처리를 실시하지 않으면 문서마다 출현한 올바른 단어수를 얻을 수 없거나 문서에서 의미가 없는 조사나 조동사가 제일 많다는 결과가 나오기 때문입니다.
이 방법은 이해하기 쉽고 간단하지만 단어 수를 계산하는 특성상 문서가 긴 것이 더 유리하다는 단점이 있습니다.
그래서 가중치에 초점을 맞춘 것이 다음 기법입니다.
- Term Frequency - Inverse Document Frequency (TF-IDF)
TF-IDF는 문서에서 단어의 중요도를 평가하는 기술입니다.
TF와 IDF라는 2개의 값의 곱을 이용한 것으로 되어 있습니다.
각각의 설명을 하면
- TF: 단어 출현 빈도. 한 문서의 한 단어의 출현 횟수 / 한 문서의 전체 단어의 출현 횟수의 합을 구하여 한 단어의 중요도를 수치화합니다.
- IDF: 역문서 빈도. 한 단어가 포함된 문서수/총 문서수(DF)의 역수를 취하고 문장의 규모에 대한 IDF값의 변화를 작게 하기 위해 로그를 취한 것
이 기법에도 단점이 있어, 그것은 문서의 집합체 안에서의 문서의 길이에 의해 TF값이 영향을 받게 된다는 것입니다. 그러나 이 단점을 보완하기 위해 TF-IDF를 개량한 「Okapi BM25」라는 수법이 태어났습니다.
여기까지 카운트 베이스의 수법을 소개해 왔습니다만, 이러한 수법에서는 문서 자체의 유사도가 요구되지만 각 단어의 유사도는 요구되지 않습니다.
그래서, 다음부터 소개하는 분산 표현을 이용하는 수법이 태어났습니다.
분산 표현을 이용한 기법
분산 표현은 단어 자체를 벡터에 매핑하는 것입니다. 이것을 이용해 단어 마다의 유사도를 구할 수 있는 수법입니다.
2013년에 Google이 발표한 Word2Vec 이 유명한 것으로 우선 들 수 있습니다.
이것은 "어떤 단어의 전후에 있는 단어는 관련성이 높은 단어일 가능성이 높다"라는 분포 가설을 이용한 수법이 되고 있습니다.
Word2Vec에는 중심이 되는 단어로부터 전후의 단어를 예측하는 「Skip-Gram」모델과 그 반대인 전후의 단어로부터 중심이 되는 단어를 예측하는 「Countinuous Bag-of-Words(CBOW)」모델이 존재 합니다.
자연언어 처리 이외에도 사용할 수 있는 방법으로서 최근이라면 Transformer 나, 자연언어 처리 분야에 있어서는 Transformer를 베이스로 한 BERT , GPT3 등이 유명합니다.
자 이제 우리가 요세 관심을 갖고 찾아 보고 있던, GPT 이야기가 나옵니다. 얼마전에 GPT3을 개발하고 있는 Open AI가 발표한 대화에 최적화된 모델인 ChatGPT를 발표한 것 그리고 인터넷에 이슈가 되어가는 덕에 이 복잡해 보이는 자연어처리라는 이야기까지 관심을 갖게된 것이니깐요 .
벡터화는 자연 언어 처리에서 반드시 통과하는 길
이와 같이 문서를 벡터화함으로써 단어의 관련성이나 문서의 관련성을 찾아내는 기법은 검색이나 감정 분석 등 다양한 것에 이용됩니다.
간단하게 인공지능을 위한 자연언어 처리의 개요 및 필요하게 되는 벡터화에 대해서 간단하게 정리해 보았습니다.
자연어 처리 기술은 더욱 발전하여 인간의 언어 이해 능력을 뛰어넘을 수 있을 것으로 예상됩니다.
특히 딥 러닝을 활용한 자연어 처리 분야는 최근 빠르게 발전하고 있으며, 기존에는 인간의 지식과 경험에 의존하였던 언어 이해와 생성 작업을 데이터 기반으로 대체하는 방향으로 나아가고 있습니다.
또한, 대화형 인터페이스 및 챗봇 등을 비롯한 인간과 컴퓨터 간의 상호작용 분야에서도 더욱 발전할 것으로 예상됩니다.
이러한 기술 발전은 자연어 처리 기술이 적용되는 광범위한 분야에서 혁신적인 변화를 가져올 것으로 예상됩니다.